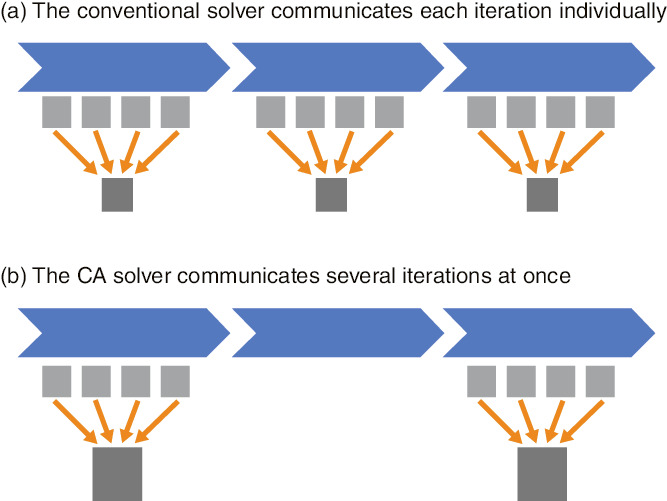
Fig.9-2 Representations of calculation and communication by the conventional and CA solvers
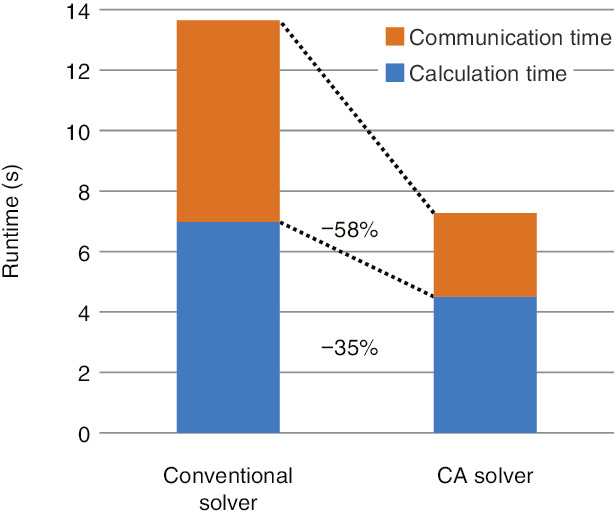
Fig.9-3 Parallel-performance comparison of the conventional and CA solvers
We promote the development of a multiphase thermal-hydraulic computational fluid dynamics (CFD) code for analyzing the relocation of molten materials in nuclear reactors during severe accidents. Current supercomputers can simulate the melt-relocation behavior of several fuel assemblies. However, to analyze a severe accident for the whole reactor-pressure vessel, we need exa-scale computers that can perform calculations more than 100 times faster than current supercomputers.
Current supercomputers are based on distributed-memory parallelism with tens of thousands of computers connected by a network. In order to make full use of the supercomputers’ performance, it is necessary to communicate the calculated data and synchronize the steps of processing; however, the communication cost is a bottleneck in exa-scale computers. In multiphase CFD code, the matrix solver for the pressure equation accounts for most of the computational cost. Since the communicational cost of the conventional solver is relatively large, the communication bottleneck becomes obvious in large-scale parallel computation. We developed the communication-avoiding (CA) matrix solver to resolve this issue and further enable large-scale CFD code analysis.
The conventional matrix solver uses the conjugate-gradient (CG) method, an iterative technique. The CG method solves a large-scale matrix problem by calculating the residual of the approximate solution and modifying the solution. The conventional solver requires inner-product operations with global communications, which collect data calculated by tens of thousands of computers per iteration (Fig.9-2(a)).
However, by communicating the data required for inner-product calculation only once for several iterations by changing the algorithm that is mathematically equivalent to the conventional solver, the CA solver can reduce the number of collective communications and synchronizations to a fraction of that of the conventional solver (Fig.9-2(b)). Despite this algorithm change causing the computational cost to become larger, the CA algorithm is suitable because the communication cost is significantly higher than the computational cost in massively parallel processing. We evaluated our CA solver’s performance on the K computer, which is the representative supercomputer in Japan. Because of the tens of thousands of computers involved in massively parallel processing, the communication cost manifested in the conventional solver was greatly reduced. In addition, the changed algorithm decreased the number of memory accesses, accelerating the calculation time and doubling the total performance (Fig.9-3).
We will develop the CA solver for a general matrix library and provide it to the community. The present study was sponsored by the Ministry of Education, Culture, Sports, Science and Technology (MEXT), Japan, Post-K Priority Issue 6, “Accelerated Development of Innovative Clean Energy Systems”.
<Previous: 9 Computational Science and E-Systems Research | Next: 9-2>

