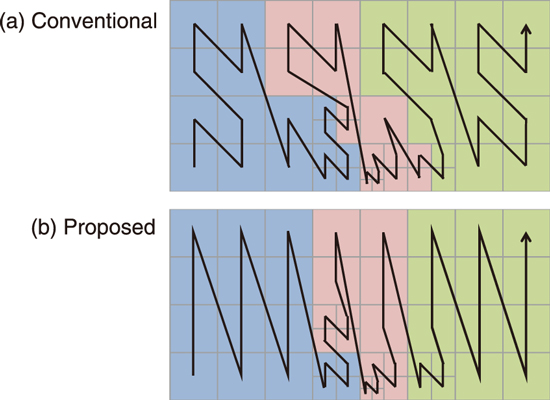
Fig.9-4 Domain partitioning on local mesh refinement (LMR)
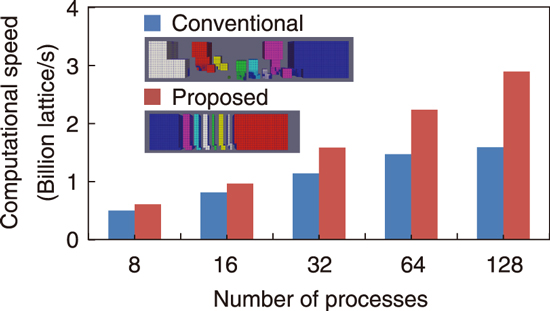
Fig.9-5 Comparison of the domain shape and computation speed
Fluid dynamics phenomena, such as wind around objects and walls, are multiscale phenomena in which a global flow feature over distant regions and local tiny eddies near the wall appear simultaneously. For simulating such phenomena, the JAEA and Tokyo Institute of Technology (Tokyo Tech) developed a computational fluid dynamics (CFD) code based on the local mesh refinement (LMR) method, which changes the mesh resolution as per the scale of the flow property. The LMR-CFD code had been first developed at Tokyo Tech, and in this study, the JAEA proposed a new domain-partitioning approach to improve the computational speed.
The LMR generates locally subdivided grids by repeatedly subdividing one grid into eight grids as per the required resolution for each region. By employing a high-resolution mesh only near the object, the number of grids in the LMR was drastically reduced to 0.715% compared to that in the uniform mesh. However, domain partitioning in parallel computing with multiple processes remained a problem.
The conventional method used a single space-filling curve (SFC) for domain partitioning (Fig.9-4(a)). The SFC is a mathematical representation of a so-called one-stroke writing, and in Fig.9-4, the SFC automatically generates an N-shaped tracing over all the grids. Because of its simplicity, the SFC is widely used for domain partitioning in the LMR; however, when the SFC generates subdomains with complex geometries (as in Fig.9-5), the amount of communication (i.e., the cross section of each subdomain) and the number of connections (i.e., the number of neighbors in each subdomain) becomes huge.
To improve the domain partitioning, this study proposes a new domain-partitioning approach, which at first partitions the domain into coarse orthogonal grids and generates local SFCs in each coarse partitioned domain and subsequently connects them to construct a one-stroke writing in different order (Fig.9-4(b)). The proposed method reduced both the amount of communication and number of connections to 1/3 and 1/2–1/3 times, respectively, those of the conventional method. These improvements enhanced the parallel performance well and resulted in ×1.82 speedup in the simulation with parallel computation involving 184 million grids using 128 processes (Fig.9-5).
This work was supported in part by JSPS KAKENHI Grant-in-Aid for Scientific Research (S) (JP26220002), Grant-in-Aid for Research Activity Start-up (JP19K24359), Grant-in-Aid for Early-Career Scientists (JP21K17755), High Performance Computing Infrastructure (Project ID: hp180146), and Joint Usage/Research Center for Interdisciplinary Large-Scale Information Infrastructures (Project ID: jh200050).
(Yuta Hasegawa)

