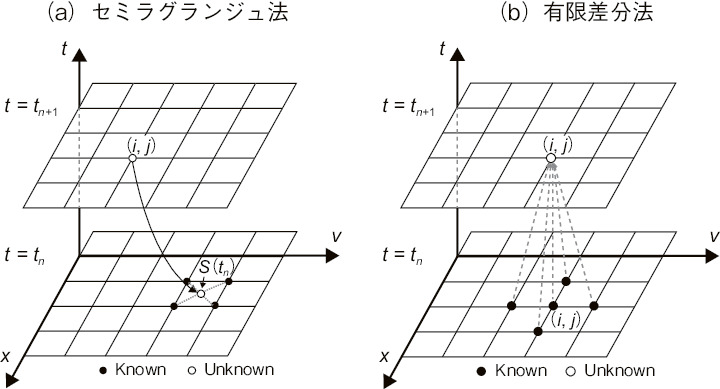
図9-4 流体計算カーネルの数値計算法
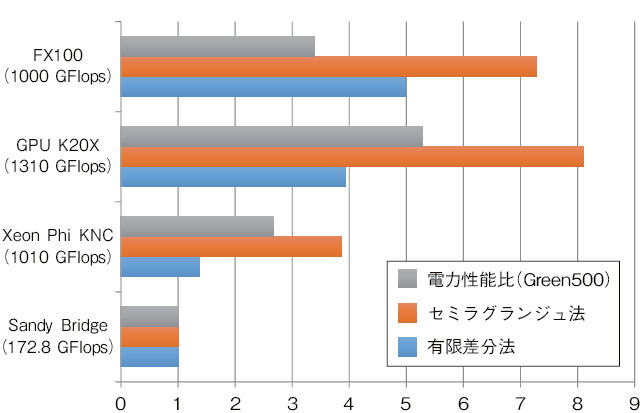
図9-5 アクセラレータにおける流体計算カーネルの計算性能比較
過酷事故の解析や放射性物質の環境動態解析等、原子力分野の流体計算をさらに高度化し、実問題に適用するには高い計算性能が必要となります。「京」コンピュータの後継機であるポスト「京」をはじめとするエクサスケール計算機の開発が国内外で進展していますが、現在の100倍以上の計算性能を同程度の消費電力で実現するために、省電力計算技術が大きな課題となっています。ハードウェアに関しては、動作周波数を抑制し、多数の演算コアを集積することによって省電力と計算性能向上を両立するアクセラレータが開発されてきました。しかしながら、ソフトウェアに関しては、アクセラレータで既存の数値計算手法を効率的に処理できるかどうか分かっていませんでした。今回、原子力流体計算コードの計算カーネルをアクセラレータ向けに最適化し、その性能を評価しました。
アクセラレータとしては、画像処理用に開発されたGPU及びCPUをベースに演算コア数を拡張した2種類のメニーコアプロセッサ、Xeon Phi、FX100を使用し、代表的な流体計算手法である有限差分法及びセミラグランジュ法の移流計算カーネルを最適化しました。有限差分法は規則的にメモリにアクセスするのに対し、セミラグランジュ法は流線に沿って解を追跡するためにランダムなメモリアクセスとなります(図9-4)。上記アクセラレータは従来のCPUに比べて消費電力あたりの計算性能を3〜5倍向上していますが(図9-5)、多数の演算コアにデータを供給するために複雑な階層構造のメモリを搭載しています。このため、階層的メモリ構造と移流計算の物理的特徴の両者を理解した上で、メモリアクセスパターンを階層的メモリ構造に適合させることが、最適化の鍵となります。
FX100は従来のCPUと同型のプロセッサ内共有メモリとなるため、特別な最適化なしに性能を引き出せることが分かりました。一方、Xeon Phiは演算コアごとに分散したメモリ構造となるため、各コアに格納されたデータを効率的に利用する演算順序の設計により1.3倍程度、GPUでは画像処理用のメモリ構造を活用するアルゴリズム設計により1.9倍程度の性能向上が得られました。以上の最適化により、有限差分法で最大5倍、セミラグランジュ法で最大8倍という高い計算性能を達成し(図9-5)、アクセラレータによる省電力計算の見通しが得られました。
本研究は、文部科学省ポスト「京」重点課題⑥「革新的クリーンエネルギーの実用化」で得られた成果です。

