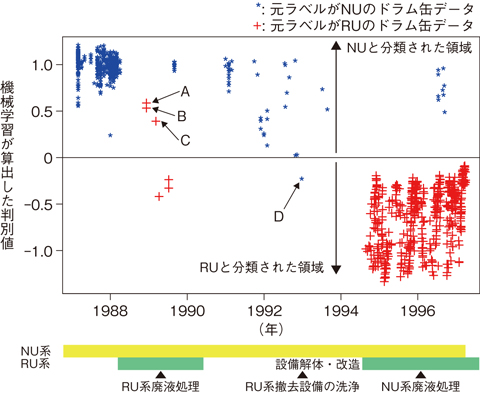
図8-4 元のラベルと機械学習による分類結果の比較
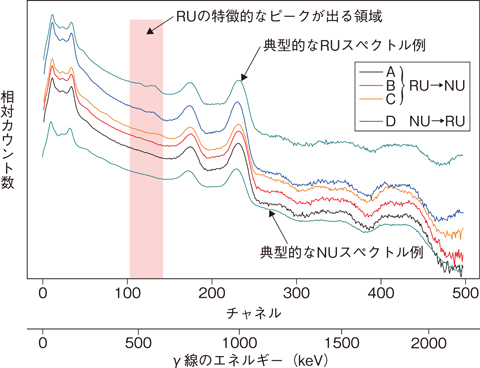
図8-5 元のラベルと異なる分類結果となった4例と典型的なNU, RUのγ線スペクトルの比較
データのもつ特徴をコンピュータが自動的に見つけ、それに基づいてデータを理解したり、予測したりする手法を機械学習といいます。そのうち、あらかじめ決められた区分のどれに属するか識別することを、パターン認識といいます。私たちは、サポートベクターマシンと呼ばれるパターン認識手法により、ドラム缶の外側から計測したγ線スペクトルの特徴を識別して、内容物ごとにドラム缶を仕分けする方法について検討しました。
人形峠環境技術センターが保管しているドラム缶の内容物は、ウラン鉱石から抽出した天然のウラン(NU)に由来するものと、一度使用した燃料から回収したウラン(RU)に由来するものがあります。NUとRUとでは、放射性核種の割合(核種組成)が大きく異なります。一般に、ウラン(U)をγ線計測すると、NU, RUとも238Uの子孫核種に由来する766, 1001 keVのピークが確認できます。RUでは、これらに加えて232U,236Uの子孫核種に由来する238, 510, 583 keVなどのピークが確認できます。
この研究では、ウラン鉱石やイエローケーキなどから六フッ化ウラン(UF6)を製造する製錬転換施設の廃水処理工程で発生した中和沈澱物を保管しているドラム缶967本のデータを利用しました。これらは、Uの由来によりNUまたはRUのラベルで分類・保管してきたものです。12個のドラム缶を選んで、NaIシンチレーション検出器で計測したγ線スペクトルとラベルの分類との関係について“学習”し、残りの955個のγ線スペクトルをNUまたはRUに仕分けました。この間1秒もかかりませんでした。その結果、ラベルと異なる区分に分類されたものが4例ありました。図8-4では、RUの特徴が明瞭なものほど大きな負の判別値となり、不明瞭なものほど大きな正の判別値となっています。4例について、運転履歴などを含めて詳細に検討したところ、1例は元のラベルの誤りで、3例は本法の誤分類であることが分かりました(図8-5)。
本法の適用により、大量のデータを短時間に、99%以上の正答率で、内容物ごとにドラム缶を仕分けることが可能であると確認できました。また、識別結果を数値化できるため、特に境界領域で、客観的な分類指標を提供できることが最大の利点です。サポートベクターマシンは、ドラム缶の内容物を分類する支援ツールとして有効な手法であり、今後、ほかの区分の分類可能性についても検討する予定です。

