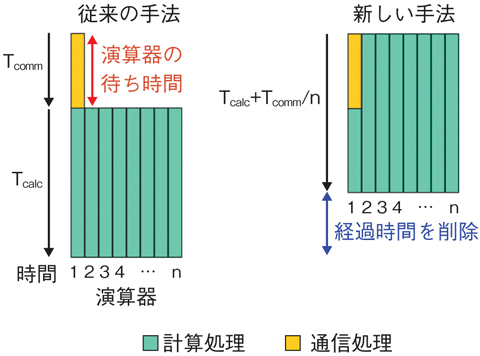
図11-6 n個の演算器を搭載した計算機における計算処理と通信処理のスケジューリング
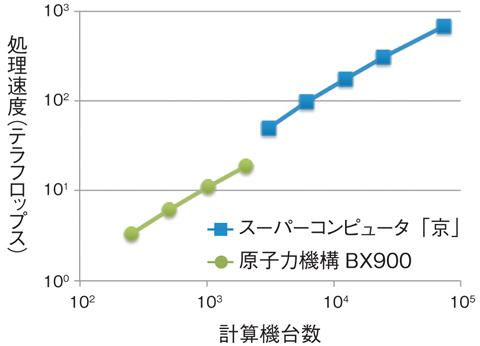
図11-7 原子力機構BX900とスーパーコンピュータ「京」における核融合プラズマシミュレーションの処理速度(テラフロップス=1秒間に1012回の演算を実行する速度)
核融合炉心プラズマの閉じ込め性能はプラズマ乱流現象によって決定されるため、ITERの性能を評価する上でシミュレーションによるプラズマ乱流の予測が重要な課題となっています。核融合プラズマの計算モデルは五次元位相空間(三次元位置×二次元速度)における燃料プラズマの分布関数の発展を取り扱うため、五次元位相空間を格子で表現するとJT-60Uのような既存装置で3003×128×32〜1011自由度となるのに対し、この数倍の装置サイズのITERでは更に1桁以上大きい自由度の乱流計算が必要となります。並列計算機の登場によってこのような膨大な計算量のシミュレーションが可能となりプラズマ乱流現象の研究が進展してきましたが、さらに、スーパーコンピュータ「京」に代表される次世代型の超並列計算機によってITERのような大型装置のシミュレーションが視野に入ってきました。しかしながら、従来の並列計算に比べて1桁多い数万台の計算機を接続した超並列計算では計算機間の通信処理が増大し、処理性能を向上する上でのボトルネックとなっていました。
そこで、計算機間の通信時間を大幅に低減する技術を開発しました。乱流計算のような格子を用いるシミュレーションでは格子データを細かい領域に分割して各計算機に割り当てて計算モデルを並列に処理します。この処理は、通常、隣接する格子のデータを必要とするため、従来の手法では計算機間で境界データの通信処理を完了してから計算処理を行っていました。この方法では通信中に計算機が待ち状態となるため、計算機の処理効率が低下します。一方、新しい手法では計算機内部の複数の演算器に通信と演算という異なる機能を割り当てて、通信処理と同時に計算処理を実行することによって計算処理の効率を向上しました(図11-6)。この手法によってスーパーコンピュータ「京」上の73728台の計算機を接続した超並列核融合プラズマシミュレーションを実現し、従来の35倍という処理速度の向上を達成しました(図11-7)。
これにより、従来の計算機では1年以上かかるITER規模の解析を1週間程度で行う見通しが得られました。
本研究は、文部科学省「HPCI戦略プログラム分野4次世代ものづくり」による国立大学法人東京大学への委託事業「計算科学技術体制構築」の一部として原子力機構が再委託を受けて実施した「次世代計算科学ソフトウェアの革新的アルゴリズムの創生と核融合プラズマ流体解析への応用」の成果の一部です。

