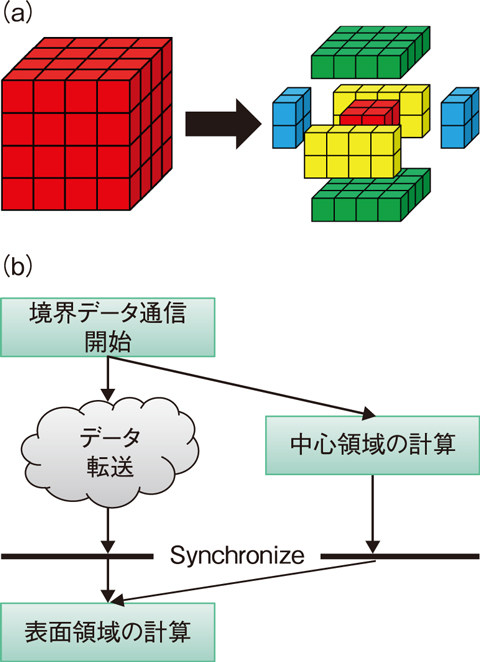
図9-7 通信オーバーラップ手法の模式図
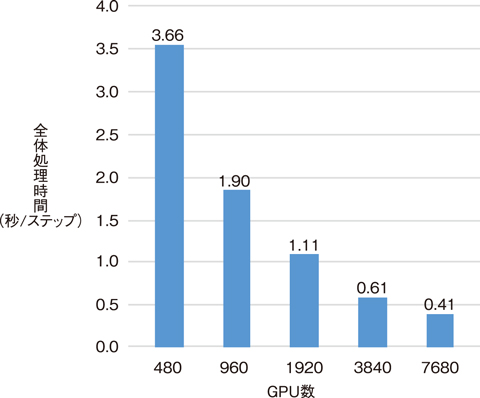
図9-8 GPUスパコンSummitにおける計算性能のスケーリング
原子炉内の複雑な熱流動現象を解析するために数値流体解析(CFD)コードの高性能化が必要とされています。従来のCFDコードは主にペタスケールのCPU計算機で開発されてきましたが、今後、解析を数千億格子規模に拡大するためにGPUを搭載したエクサスケール計算機の活用が必須となります。しかしながら、GPU計算機では演算器の集積度向上によって演算性能は従来のCPUの数十倍となるのに対し、プロセッサ間の通信性能は数倍程度の向上に留まっており、演算と通信のバランスの変化に対応できる新たな省通信型計算手法の開発が課題となっていました。今回、CFDコードの中核を成す行列計算のGPU計算機向け計算手法を開発し、オークリッジ国立研究所に設置された世界最大のGPU計算機Summitにおいて、7680台のGPUを用いた大規模多相流体解析の高速化に成功しました。
CFDコードでは差分法による流体モデルの離散化で得られる大規模行列問題を計算します。本研究では、従来、共役勾配(CG)法と呼ばれる反復行列解法を利用していましたが、CG法の並列計算には分割領域上の差分計算に必要な境界データ通信、及び行列解法で計算するベクトルの内積処理のための縮約通信という二つの通信処理が反復ごとに必要となります。これらの通信処理を削減するために、本研究では二つの手法、通信オーバーラップ手法及び省通信型CG法を用いました。境界データ通信に関しては、図9-7に示すように各GPU上の計算領域を中心部分と表面部分に分割し、境界データを参照しない中心部分の差分計算と境界データ通信を同時処理する通信オーバーラップ手法を開発し、通信コストを隠蔽しました。一方、縮約通信に関してはCG法の数学的なアルゴリズム改良によってベクトルの内積処理を複数反復ごとに一度に処理する省通信型CG法を適用し、通信回数を一桁削減しました。
Summitにおいて燃料集合体の溶融挙動を模擬する多相流体解析(約75億格子、燃料集合体4体規模)を実施し、開発手法の性能評価を実施しました。この結果、図9-8に示すようにGPU数480台から7680台まで計算性能が約9倍加速し、目標通りの良好なスケーリングが確認できました。
本研究は、Oak Ridge Leadership Computing Facility(OLCF)Director’s Discretion Project「Exascale CFD Simulations at JAEA(CSC367)」の支援の下で得られた成果です。
(井戸村 泰宏)

